Threaded Assembly
This example is also available as a Jupyter notebook: threaded_assembly.ipynb.
Example of a colored grid
Creates a simple 2D grid and colors it. Save the example grid to a VTK file to show the coloring. No cells with the same color has any shared nodes (dofs). This means that it is safe to assemble in parallel as long as we only assemble one color at a time.
For this structured grid the greedy algorithm uses fewer colors, but both algorithms result in colors that contain roughly the same number of elements. For unstructured grids the greedy algorithm can result in colors with very few element. For those cases the workstream algorithm is better since it tries to balance the colors evenly.
using Ferrite, SparseArrays
function create_example_2d_grid()
grid = generate_grid(Quadrilateral, (10, 10), Vec{2}((0.0, 0.0)), Vec{2}((10.0, 10.0)))
colors_workstream = create_coloring(grid; alg=ColoringAlgorithm.WorkStream)
colors_greedy = create_coloring(grid; alg=ColoringAlgorithm.Greedy)
vtk_grid("colored", grid) do vtk
vtk_cell_data_colors(vtk, colors_workstream, "workstream-coloring")
vtk_cell_data_colors(vtk, colors_greedy, "greedy-coloring")
end
end
create_example_2d_grid();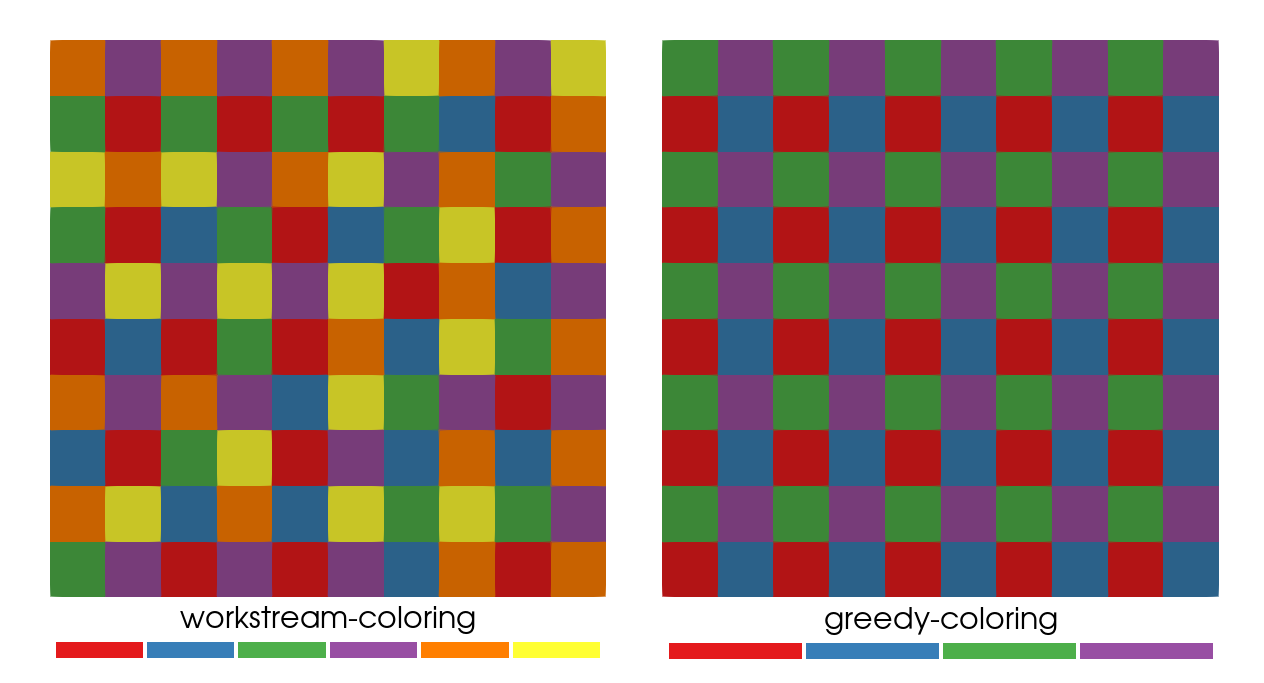
Figure 1: Element coloring using the "workstream"-algorithm (left) and the "greedy"- algorithm (right).
Cantilever beam in 3D with threaded assembly
We will now look at an example where we assemble the stiffness matrix using multiple threads. We set up a simple grid and create a coloring, then create a DofHandler, and define the material stiffness
Grid for the beam
function create_colored_cantilever_grid(celltype, n)
grid = generate_grid(celltype, (10*n, n, n), Vec{3}((0.0, 0.0, 0.0)), Vec{3}((10.0, 1.0, 1.0)))
colors = create_coloring(grid)
return grid, colors
end;DofHandler
function create_dofhandler(grid::Grid{dim}) where {dim}
dh = DofHandler(grid)
add!(dh, :u, dim) # Add a displacement field
close!(dh)
end;Stiffness tensor for linear elasticity
function create_stiffness(::Val{dim}) where {dim}
E = 200e9
ν = 0.3
λ = E*ν / ((1+ν) * (1 - 2ν))
μ = E / (2(1+ν))
δ(i,j) = i == j ? 1.0 : 0.0
g(i,j,k,l) = λ*δ(i,j)*δ(k,l) + μ*(δ(i,k)*δ(j,l) + δ(i,l)*δ(j,k))
C = SymmetricTensor{4, dim}(g);
return C
end;Threaded data structures
ScratchValues is a thread-local collection of data that each thread needs to own, since we need to be able to mutate the data in the threads independently
struct ScratchValues{T, CV <: CellValues, FV <: FaceValues, TT <: AbstractTensor, dim, Ti}
Ke::Matrix{T}
fe::Vector{T}
cellvalues::CV
facevalues::FV
global_dofs::Vector{Int}
ɛ::Vector{TT}
coordinates::Vector{Vec{dim, T}}
assembler::Ferrite.AssemblerSparsityPattern{T, Ti}
end;Each thread need its own CellValues and FaceValues (although, for this example we don't use the FaceValues)
function create_values(refshape, dim, order::Int)
# Interpolations and values
interpolation_space = Lagrange{dim, refshape, 1}()
quadrature_rule = QuadratureRule{dim, refshape}(order)
face_quadrature_rule = QuadratureRule{dim-1, refshape}(order)
cellvalues = [CellVectorValues(quadrature_rule, interpolation_space) for i in 1:Threads.nthreads()];
facevalues = [FaceVectorValues(face_quadrature_rule, interpolation_space) for i in 1:Threads.nthreads()];
return cellvalues, facevalues
end;Create a ScratchValues for each thread with the thread local data
function create_scratchvalues(K, f, dh::DofHandler{dim}) where {dim}
nthreads = Threads.nthreads()
assemblers = [start_assemble(K, f) for i in 1:nthreads]
cellvalues, facevalues = create_values(RefCube, dim, 2)
n_basefuncs = getnbasefunctions(cellvalues[1])
global_dofs = [zeros(Int, ndofs_per_cell(dh)) for i in 1:nthreads]
fes = [zeros(n_basefuncs) for i in 1:nthreads] # Local force vector
Kes = [zeros(n_basefuncs, n_basefuncs) for i in 1:nthreads]
ɛs = [[zero(SymmetricTensor{2, dim}) for i in 1:n_basefuncs] for i in 1:nthreads]
coordinates = [[zero(Vec{dim}) for i in 1:length(dh.grid.cells[1].nodes)] for i in 1:nthreads]
return [ScratchValues(Kes[i], fes[i], cellvalues[i], facevalues[i], global_dofs[i],
ɛs[i], coordinates[i], assemblers[i]) for i in 1:nthreads]
end;Threaded assemble
The assembly function loops over each color and does a threaded assembly for that color
function doassemble(K::SparseMatrixCSC, colors, grid::Grid, dh::DofHandler, C::SymmetricTensor{4, dim}) where {dim}
f = zeros(ndofs(dh))
scratches = create_scratchvalues(K, f, dh)
b = Vec{3}((0.0, 0.0, 0.0)) # Body force
for color in colors
# Each color is safe to assemble threaded
Threads.@threads :static for i in 1:length(color)
assemble_cell!(scratches[Threads.threadid()], color[i], K, grid, dh, C, b)
end
end
return K, f
enddoassemble (generic function with 1 method)The cell assembly function is written the same way as if it was a single threaded example. The only difference is that we unpack the variables from our scratch.
function assemble_cell!(scratch::ScratchValues, cell::Int, K::SparseMatrixCSC,
grid::Grid, dh::DofHandler, C::SymmetricTensor{4, dim}, b::Vec{dim}) where {dim}
# Unpack our stuff from the scratch
Ke, fe, cellvalues, facevalues, global_dofs, ɛ, coordinates, assembler =
scratch.Ke, scratch.fe, scratch.cellvalues, scratch.facevalues,
scratch.global_dofs, scratch.ɛ, scratch.coordinates, scratch.assembler
fill!(Ke, 0)
fill!(fe, 0)
n_basefuncs = getnbasefunctions(cellvalues)
# Fill up the coordinates
nodeids = grid.cells[cell].nodes
for j in 1:length(coordinates)
coordinates[j] = grid.nodes[nodeids[j]].x
end
reinit!(cellvalues, coordinates)
for q_point in 1:getnquadpoints(cellvalues)
for i in 1:n_basefuncs
ɛ[i] = symmetric(shape_gradient(cellvalues, q_point, i))
end
dΩ = getdetJdV(cellvalues, q_point)
for i in 1:n_basefuncs
δu = shape_value(cellvalues, q_point, i)
fe[i] += (δu ⋅ b) * dΩ
ɛC = ɛ[i] ⊡ C
for j in 1:n_basefuncs
Ke[i, j] += (ɛC ⊡ ɛ[j]) * dΩ
end
end
end
celldofs!(global_dofs, dh, cell)
assemble!(assembler, global_dofs, fe, Ke)
end;
function run_assemble()
refshape = RefCube
quadrature_order = 2
dim = 3
n = 20
grid, colors = create_colored_cantilever_grid(Hexahedron, n);
dh = create_dofhandler(grid);
K = create_sparsity_pattern(dh);
C = create_stiffness(Val{3}());
# compilation
doassemble(K, colors, grid, dh, C);
b = @elapsed @time K, f = doassemble(K, colors, grid, dh, C);
return b
end
run_assemble()2.096623869Running the code with different number of threads give the following runtimes:
- 1 thread 2.46 seconds
- 2 threads 1.19 seconds
- 3 threads 0.83 seconds
- 4 threads 0.75 seconds
Plain program
Here follows a version of the program without any comments. The file is also available here: threaded_assembly.jl.
using Ferrite, SparseArrays
function create_example_2d_grid()
grid = generate_grid(Quadrilateral, (10, 10), Vec{2}((0.0, 0.0)), Vec{2}((10.0, 10.0)))
colors_workstream = create_coloring(grid; alg=ColoringAlgorithm.WorkStream)
colors_greedy = create_coloring(grid; alg=ColoringAlgorithm.Greedy)
vtk_grid("colored", grid) do vtk
vtk_cell_data_colors(vtk, colors_workstream, "workstream-coloring")
vtk_cell_data_colors(vtk, colors_greedy, "greedy-coloring")
end
end
create_example_2d_grid();
function create_colored_cantilever_grid(celltype, n)
grid = generate_grid(celltype, (10*n, n, n), Vec{3}((0.0, 0.0, 0.0)), Vec{3}((10.0, 1.0, 1.0)))
colors = create_coloring(grid)
return grid, colors
end;
function create_dofhandler(grid::Grid{dim}) where {dim}
dh = DofHandler(grid)
add!(dh, :u, dim) # Add a displacement field
close!(dh)
end;
function create_stiffness(::Val{dim}) where {dim}
E = 200e9
ν = 0.3
λ = E*ν / ((1+ν) * (1 - 2ν))
μ = E / (2(1+ν))
δ(i,j) = i == j ? 1.0 : 0.0
g(i,j,k,l) = λ*δ(i,j)*δ(k,l) + μ*(δ(i,k)*δ(j,l) + δ(i,l)*δ(j,k))
C = SymmetricTensor{4, dim}(g);
return C
end;
struct ScratchValues{T, CV <: CellValues, FV <: FaceValues, TT <: AbstractTensor, dim, Ti}
Ke::Matrix{T}
fe::Vector{T}
cellvalues::CV
facevalues::FV
global_dofs::Vector{Int}
ɛ::Vector{TT}
coordinates::Vector{Vec{dim, T}}
assembler::Ferrite.AssemblerSparsityPattern{T, Ti}
end;
function create_values(refshape, dim, order::Int)
# Interpolations and values
interpolation_space = Lagrange{dim, refshape, 1}()
quadrature_rule = QuadratureRule{dim, refshape}(order)
face_quadrature_rule = QuadratureRule{dim-1, refshape}(order)
cellvalues = [CellVectorValues(quadrature_rule, interpolation_space) for i in 1:Threads.nthreads()];
facevalues = [FaceVectorValues(face_quadrature_rule, interpolation_space) for i in 1:Threads.nthreads()];
return cellvalues, facevalues
end;
function create_scratchvalues(K, f, dh::DofHandler{dim}) where {dim}
nthreads = Threads.nthreads()
assemblers = [start_assemble(K, f) for i in 1:nthreads]
cellvalues, facevalues = create_values(RefCube, dim, 2)
n_basefuncs = getnbasefunctions(cellvalues[1])
global_dofs = [zeros(Int, ndofs_per_cell(dh)) for i in 1:nthreads]
fes = [zeros(n_basefuncs) for i in 1:nthreads] # Local force vector
Kes = [zeros(n_basefuncs, n_basefuncs) for i in 1:nthreads]
ɛs = [[zero(SymmetricTensor{2, dim}) for i in 1:n_basefuncs] for i in 1:nthreads]
coordinates = [[zero(Vec{dim}) for i in 1:length(dh.grid.cells[1].nodes)] for i in 1:nthreads]
return [ScratchValues(Kes[i], fes[i], cellvalues[i], facevalues[i], global_dofs[i],
ɛs[i], coordinates[i], assemblers[i]) for i in 1:nthreads]
end;
function doassemble(K::SparseMatrixCSC, colors, grid::Grid, dh::DofHandler, C::SymmetricTensor{4, dim}) where {dim}
f = zeros(ndofs(dh))
scratches = create_scratchvalues(K, f, dh)
b = Vec{3}((0.0, 0.0, 0.0)) # Body force
for color in colors
# Each color is safe to assemble threaded
Threads.@threads :static for i in 1:length(color)
assemble_cell!(scratches[Threads.threadid()], color[i], K, grid, dh, C, b)
end
end
return K, f
end
function assemble_cell!(scratch::ScratchValues, cell::Int, K::SparseMatrixCSC,
grid::Grid, dh::DofHandler, C::SymmetricTensor{4, dim}, b::Vec{dim}) where {dim}
# Unpack our stuff from the scratch
Ke, fe, cellvalues, facevalues, global_dofs, ɛ, coordinates, assembler =
scratch.Ke, scratch.fe, scratch.cellvalues, scratch.facevalues,
scratch.global_dofs, scratch.ɛ, scratch.coordinates, scratch.assembler
fill!(Ke, 0)
fill!(fe, 0)
n_basefuncs = getnbasefunctions(cellvalues)
# Fill up the coordinates
nodeids = grid.cells[cell].nodes
for j in 1:length(coordinates)
coordinates[j] = grid.nodes[nodeids[j]].x
end
reinit!(cellvalues, coordinates)
for q_point in 1:getnquadpoints(cellvalues)
for i in 1:n_basefuncs
ɛ[i] = symmetric(shape_gradient(cellvalues, q_point, i))
end
dΩ = getdetJdV(cellvalues, q_point)
for i in 1:n_basefuncs
δu = shape_value(cellvalues, q_point, i)
fe[i] += (δu ⋅ b) * dΩ
ɛC = ɛ[i] ⊡ C
for j in 1:n_basefuncs
Ke[i, j] += (ɛC ⊡ ɛ[j]) * dΩ
end
end
end
celldofs!(global_dofs, dh, cell)
assemble!(assembler, global_dofs, fe, Ke)
end;
function run_assemble()
refshape = RefCube
quadrature_order = 2
dim = 3
n = 20
grid, colors = create_colored_cantilever_grid(Hexahedron, n);
dh = create_dofhandler(grid);
K = create_sparsity_pattern(dh);
C = create_stiffness(Val{3}());
# compilation
doassemble(K, colors, grid, dh, C);
b = @elapsed @time K, f = doassemble(K, colors, grid, dh, C);
return b
end
run_assemble()This page was generated using Literate.jl.